
What is med-DECILE
Data Efficient Learning with Less Data
State of the art AI and Deep Learning are very data hungry. This comes at
significant cost including larger resource costs (multiple expensive GPUs
and cloud costs), training times (often times multiple days), and human
labeling costs and time. Med-Decile attempts to solve this by answering the
following question. Can we train state of the art deep models with only a
sample (say 5 to 10\%) of massive datasets, while having neglibible impact
in accuracy? Can we do this while reducing training time/cost by an order of
magnitude, and/or significantly reducing the amount of labeled data
required?
Need for med-DECILE
Modules

Reduce end to end training time from days to hours and hours to minutes using coresets and data selection. CORDS implements a number of state of the art data subset selection algorithms and coreset algorithms. Some of the algorithms currently implemented with CORDS include: GLISTER, GradMatchOMP, GradMatchFixed, CRAIG, SubmodularSelection, RandomSelection etc

DISTIL is a library that features many state-of-the-art active learning algorithms. Implemented in PyTorch, it gives fast and efficient implementations of these active learning algorithms. It allows users to modularly insert active learning selection into their pre-existing training loops with minimal change. Most importantly, it features promising results in achieving high model performance with less amount of labeled data. If you are looking to cut down on labeling costs, DISTIL should be your go-to for getting the most out of your data.
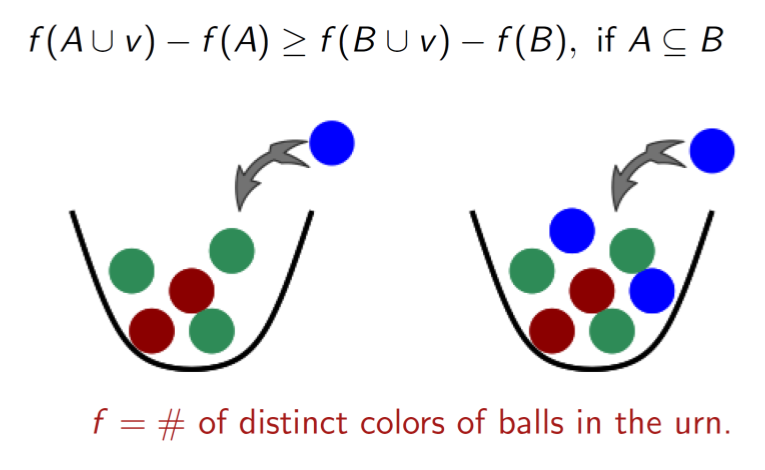


SPEAR is a python library that reduce data labeling efforts using data programming. It implements several recent approaches such as Snorkel, ImplyLoss, Learning to reweight, etc. In addition to data labeling, it integrates semi-supervised approaches for training and inference.


Team




Research Publications
International Conference on Machine Learning (ICML) 2015
7th IEEE Winter Conference on Applications of Computer Vision (WACV), 2019 Hawaii, USA
35th AAAI Conference on Artificial Intelligence, AAAI 2021
International Conference on Machine Learning (ICML 2014)
2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2014
International Conference on Machine Learning (ICML), July 2020
InProc. Advances in Neural Information Processing Systems (NeurIPS), 2020
International Conference on Machine Learning (ICML) 2015
8th International Conference on Learning Representations (ICLR), 2020
In Proceedings of the 35th AAAI Conference on Artificial Intelligence, AAAI 2021
In Proceedings of the 32th AAAI Conference on Artificial Intelligence, AAAI 2018
In Proceedings of The 7th IEEE Winter Conference on Applications of Computer Vision (WACV), 2019, Hawaii, USA
International Joint Conference on Neural Networks (IJCNN), 2014
34th International Conference on Machine Learning(ICML), 2017
6th International Conference on Learning Representations (ICLR), 2018
In Proceedings of The 7th IEEE Winter Conference on Applications of Computer Vision (WACV), 2019, Hawaii, USA.
n Proceedings of The 7th IEEE Winter Conference on Applications of Computer Vision (WACV), 2019, Hawaii, USA.
In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, Louisiana, USA.
In Proceedings of the 25th International Conference on Information and Knowledge Management (CIKM 2016), Indianapolis, USA
In Proceedings of the 20th Pacific Asia Conference on Knowledge Discovery and Data Mining (PAKDD) 2016.
In Proceedings of The Thirty-Fourth AAAI Conferenceon Artificial Intelligence (AAAI 2020), New York, USA.
In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, Louisiana, USA.
In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, Louisiana, USA.
In Proceedings of the 23rd International Conference on Inductive Logic Programming (ILP), 2013, Rio De Janerio, Brazil.
In Proceedings of the 2012 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2012, Jeju, Korea.
In Proceedings of the Twenty-Sixth Conference on Artificial Intelligence (AAAI), 2012, Toronto, Canada.
In Proceedings of the 22nd International Conference on Inductive Logic Programming (ILP), 2012, Dubrovnik
In Proceedings of the 22rd International Conference on Inductive Logic Programming (ILP), 2012
In Proceedings of the 28th International Conference on Machine Learning, 2011
In Proceedings of the 20rd International Conference on Inductive Logic Programming (ILP), Florence, Italy
In Proceedings of the 20rd International Conference on Inductive Logic Programming (ILP), Florence, Italy
In the Journal of Machine Learning Research 11 (2010) 3481-3516
In Machine Learning 76(1): 109-136 (2009)
In Proceedings of the 18th International Conference on Inductive Logic Programming (ILP 2008), Prague, Czech Republic, September 10-12, 2008